Опубликовано
- 1 мин чтения
Как данные влияют на производительность

Хочу рассказать о том, насколько важно способ инициализации данных для достижения максимальной производительности кода.
Рассмотрим следующий синтетический пример.
- Массивы
t1иt2содержат информацию о транзакциях. - Два метода,
Setup1иSetup2, инициализируют массивыt1иt2соответственно:Setup1– двумя цикламиfor, аSetup2– одним. - Метод
Sumпозволяет вычислить сумму транзакций в массивахt1илиt2.

Вопрос: при каком способе инициализации расчёт суммы в массивах Sum(t1) + Sum(t2) выполнится быстрее?
Правильный ответ: Sum(t1) + Sum(t2) рассчитывается быстрее, если массивы инициализировать двумя циклами for.
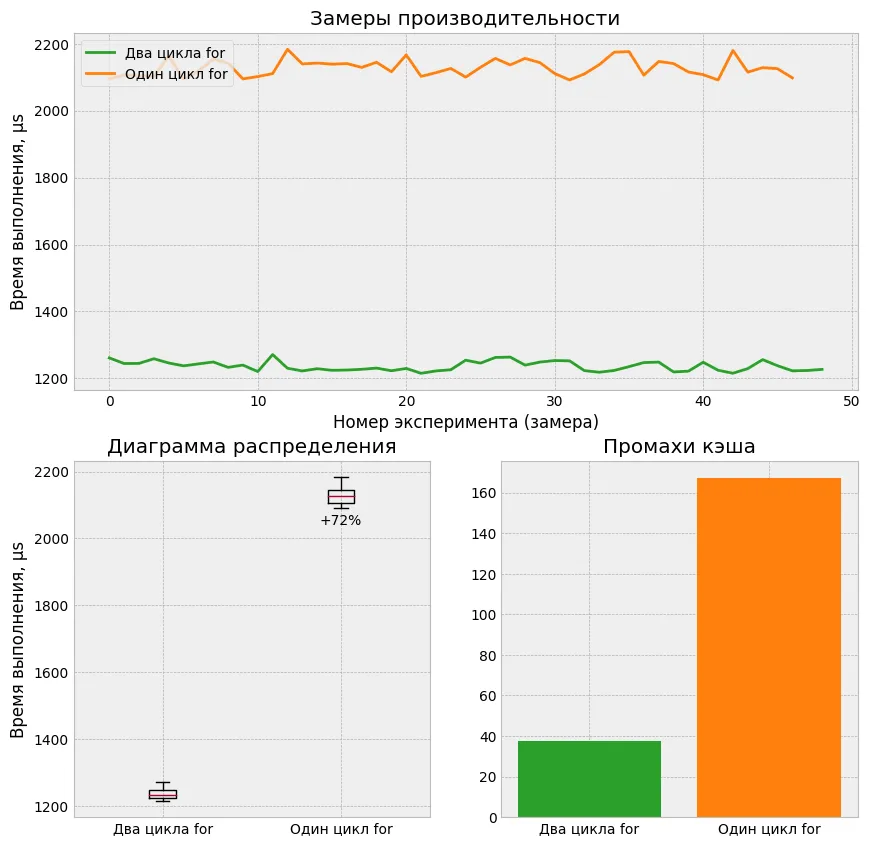
Почему так? Всё дело в кэше данных процессора. Я уже писал пост на эту тему, но тогда рассматривал два разных алгоритма для обхода одной и той же матрицы. В данном случае алгоритм не меняется, но данные инициализируются по-разному.
Если массивы t1 и t2 инициализировать одним циклом for, то в памяти это выглядит примерно так:
t1[0], t2[0], t1[1], t2[1], t1[2], t2[3], ...
При расчёте, например, Sum(t1), в самом начале происходит обращение к элементу t1[0]. Копирование данных из памяти в кэш происходит блоками по 64 байта — это размер линии кэша большинства современных процессоров. Из-за этого в кэш попадают элементы массива t2, хотя методу Sum нужны элементы только одного массива. В результате увеличивается количество промахов кэша.
Если массивы t1 и t2 инициализировать двумя циклами for, то локальность данных более высокая, что снижает количество промахов кэша:
t1[0], t1[1], t1[2], t1[3], ... t2[0], t2[1], t2[2], t2[3], ...